
Tugas 6
SYNTAX UNTUK MERELASIKAN TABEL MYSQL
DEFINISI JOIN
Join adalah penggabungan table yang dilakukan melalui kolom / key tertentu yang memiliki nilai terkait untuk mendapatkan satu set data dengan informasi lengkap. Lengkap disini artinya kolom data didapatkan dari kolom-kolom hasil join antar table tersebut.
Join diperlukan karena perancangan table pada sistem transaksional kebanyakan di-normalisasi, salah satu alasannya untuk menghindari redundansi.
1. INNER JOIN
INNER JOIN adalah tipe join yang akan kita bahas pertama. Tipe join ini akan mengambil semua row dari table asal dan table tujuan dengan kondisi nilai key yang terkait saja - jika ada, dan jika tidak maka row tersebut tidak akan muncul.
Kalau tidak terdapat kondisi key terkait antar table, maka semua row dari kedua table dikombinasikan.
Syntax dari INNER JOIN adalah sebagai berikut : ?
1 table_reference [INNER] JOIN table_factor [join_condition]
Terlihat bahwa keyword INNER boleh digunakan secara eksplisit atau tidak. Jika tidak digunakan maka konstruksi JOIN tanpa keyword lain dianggap sebagai INNER JOIN.
Secara pengerjaan relasi hampir sama dengan klusa WHERE ?
WHERE table1.referensiID = table2.referensiID
2. CROSS JOIN
Operasi cross join akan menampilkan semua isi tabel sisi sebelah kiri akan memiliki pasangan semua data sisi sebelah kanan. Banyaknya record cross join = jumlah record tabel pertama X jumlah record tabel kedua.
CROSS JOIN identik dengan INNER JOIN pada MySQL 5.0. Pembahasannya sama dengan INNER JOIN, dan karena klausa ini jarang dipakai maka tidak diulangi lagi disini.
SQL CROSS JOIN syntax:
SELECT * FROM [TABLE 1] CROSS JOIN [TABLE 2] OR SELECT * FROM [TABLE 1], [TABLE 2]
3. OUTER JOIN
Merupakan tipe join yang mencari referensi data dari suatu table sumber ke table lain dengan tidak menghilangkan data sumber apabila referensi tidak diketemukan
Syntax:
SELECT column_list
FROM table_reference
LEFT | RIGHT | FULL [OUTER] JOIN table_reference ON predicate
[LEFT | RIGHT | FULL [OUTER] JOIN table_reference ON predicate...]
.
Untuk menggunakan tipe OUTER JOIN maka perlu memperhatikan beberapa hal berikut :
Perlu dibedakan antara table sumber dan table referensi, ini ditentukan dengan cara menspesifikasikan kedudukan table sumber apakah di kiri (LEFT) atau di kanan (RIGHT).Jika tidak ada data dari table referensi yang cocok dengan kondisi join maka hanya data dari table sumber yang ditampilkan tetapi kolom-kolom table referensi akan berisi null.
LEFT JOIN
Operasi left join akan menampilkan semua isi tabel sisi kiri, walaupun data di pasangan joinnya yang disisi kanan nilainya tidak sama ataupun berisi null.
RIGHT JOIN
Operasi right join akan menampilkan semua isi tabel sisi kanan, walaupun data di pasangan joinnya yang di sisi kiri nilainya tidak sama ataupun berisi null.
STRAIGHT_JOIN
STRAIGHT_JOIN merupakan pengganti keyword JOIN pada MySQL yang digunakan untuk "memaksa" proses join table dari kiri (LEFT) ke kanan (RIGHT).
4. FULL JOIN
Operasi full join akan menampilkan semua isi tabel sisi kiri, walaupun data di pasangan joinnya yang disisi kanan nilainya null dan sebaliknya.
SYNTAX :
SELECT table1.column1, table2.column2...
FROM table1
FULL JOIN table2
ON table1.common_filed = table2.common_field;
Contoh script Full join
select d.area_id, d.nama_area, d.luas_area, p.penduduk_id, p.nama_pendudukfrom cpenduduk p full join carea d on p.area_id = d.area_id
Sumber Berita: www.muhammadcahya.com
http://www.muhammadcahya.com/post-12-pengertian-join-pada-sql.html#ixzz2Evi4kuWG
Tugas Kelompok
Relasi Sekolah
Oleh
Mersi Raha Kusumawardani Kolintama
Nur Annisa Dunggio
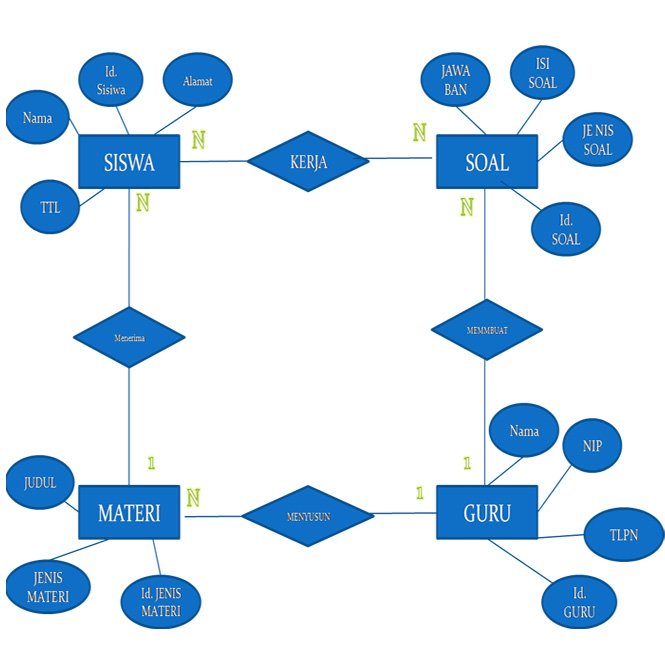
A. Entity – entiti
1. Siswa
2. Guru
3. Materi
4. Soal
B. Penentuan Atribut
1. Siswa
Nama, Tempat tanggal lahir, Alamat, Id siswa, Orangtua
2. Guru
Nama, NIP, Telfon, Id guru
3. Soal
Jawaban soal, Isi soal, Jenis soal, Id soal
4. Materi
Judul, Jenis materi, Id Materi Pelajaran
C. Relationship antar entity – entity
1. Siswa kerja soal
2. Guru menyusun materi
3. Guru membuat soal
4. Siswa Menerima materi
tugas 4
*NORMALISASI DATABASE RELASI*
Ketika kita merancang suatu basis data untuk suatu sistem relational, prioritas utama dalam mengembangkan model data logical adalah dengan merancang suatu representasi data yang tepat bagi relationship dan constrainnya (batasannya). Kita harus mengidentifikasi suatu set relasi yang cocok, demi mencapai tujuan di atas. Tehnik yang dapat kita gunakan untuk membantu mengidetifikasi relasi-relasi tersebut dianamakan Normalisasi.
Proses normalisasi pertama kali diperkenalkan oleh E.F.Codd pada tahun 1972. normalisasi sering dilakukan sebagai suatu uji coba pada suatu relasi secara berkelanjutan untuk menentukan apakah relasi tersebut sudah baik atau masih melanggar aturan-aturan standar yang diperlakukan pada suatu relasi yang normal (sudah dapat dilakukan proses insert, update, delete, dan modify pada satu atau beberapa atribut tanpa mempengaruhi integritas data dalam relasi tersebut).
Proses normalisasi merupakan metode yang formal/standar dalam mengidentifikasi dasar relasi bagi primary keynya (atau candidate key dalam kasus BCNF), dan dependensi fungsional diantara atribut-atribut dari relasi tersebut. Normalisasi akan membantu perancang basis data dengan menyediakan suatu uji coba yang berurut yang dapat diimplementasikan pada hubungnan individualshingga skema relasi dapat di normalisasi ke dalam bentuk yang lebih spesifik untuk menghindari terjadinya error atau inkonsistansi data, bila dilakuan update tehadap relasi tersebut dengan Anomaly.
BEBERAPA DEFINISI NORMALISASI
Normalisasi adalah suatu proses memperbaiki / membangun dengan model data relasional, dan secara umum lebih tepat dikoneksikan dengan model data logika
Normalisasi adalah proses pengelompokan data ke dalam bentuk tabel atau relasi atau file untuk menyatakan entitas dan hubungan mereka sehingga terwujud satu bentuk database yang mudah untuk dimodifikasi.
Normalisasi dapat berguna dalam menjawab 2 pertanyaan mendasar yaitu: “apa yang dimaksud dengan desain database logical?” dan “apa yang dimaksud dengan desain database fisikal yang baik? What is phisical good logical database design?”.
Normalisasi adalah suatu proses untuk mengidentifikasi “tabel” kelompok atribut yang memiliki ketergantungan yang sangat tinggi antara satu atribut dengan atrubut lainnya.
Normalisasi bisa disebut jga sebagai proses pengelompokan atribut-atribut dari suatu relasi sehingga membentuk WELL STRUCTURED RELATION.
WELL STRUCTURED RELATIONadalah sebuah relasi yang jumlah kerangkapan datanya sedikit (Minimum Amount Of Redundancy), serta memberikan kemungkinan bagi used untuk melakukan INSERT, DELETE, MODIFY, terhadap baris-baris data pada relasi tersebut, yang tidak berakibat terjadinya ERROR atau INKONSISTENSI DATA, yang disebabkan oleh operasi-operasi tersebut.
Contoh:
Terdapat sebuah relasi Mahasiswa, dengan ketentuan sebagai berikut.
- Setiap Mahasiswa hanya boleh mengambil satu mata kuliah saja.
- Setiap matakuliah mempunyai uang kuliah yang standar (tidak tergantung pada mahasiswa yang mengambil matakuliah tersebut).
(berhubung pada blog ini tidak dapat ditampilkan tabel yang telah saya unduh dari internet, maka disini saya hanya mengilustrasikan tabel tersebut lewat kata-kata saja)
Misalnya, terdapat 3 kolom yang masing-masingnya terdiri atas kolom NIM, kolom KODE-MTK, dan kolom BIAYA. Pada kolom pertama atau pada kolom NIM kita bisa menuliskan NIM dari si mahasiswa (mis: 921411026), kemudian pada kolom kedua atau pada kolom KODE-MTK kita bisa menuliskan kode mata kuliah yang diambil si mahasiswa (mis: CS-200), dan selanjutnya pada kolom terakhir atau pada kolom BIAYA kita bisa menuliskan jumlah biaya yang harus dibayarkan untuk setiap kode matakuliah tersebut (mis: 75.000)
Relasi Kuliah di atas merupakan sebuah relasi yang sederhana dan terdiri dari 3 kolom / atribut. Bila diteliti secara seksama, maka akan ditemukan redundancy pada datanya, dimana biaya kuliah selalu berulang pada setiap mahasiswa. Akibatnya besar kemungkinan terjadi error atau inkonsistensi data, bila dilakukan update terhadap relasi tersebut dengan Anomaly.
Anomaly merupakan penyimpangan-penyimpangan atau error atau inkonsistensi data yang terjadi pada saat dilakukan proses delete, insert ataupun modify dalam suatu basis data.
Dikutip dari :
http://bajay-x.blogspot.com/2010/05/normalisasi-database.html
LANGKAH-LANGKAH PEMBENTUKAN NORMALISASI
1. BENTUK TIDAK NORMAL (UNNORMALIZED FORM)
Bentuk ini merupakan kumpulan data yang akan direkam, tidak ada keharusan mengikukti format tertentu, dapat saja data tidak lengkap atau terduplikasi. Data dikumpulkan apa adanya sesuai dengan saat menginput. Untuk mentransformasikan tabel yang belum ternomalisasi di atas menjadi tabel yang memenuhi kriteria 1NF adalah kita harus merubah seluruh atribut yang multivalue menjadi atribut single value, dengan cara menghilangkan repeating group pada tabel di atas.
2. BENTUK NORMAL KE SATU (FIRST NORMAL FORM / 1 NF)
Pada tahap ini dilakukan penghilangan beberapa group elemen yang berulang agar menjadi satu harga tunggal yang berinteraksi di antara setiap baris pada suatu tabel, dan setiap atribut harus mempunyai nilai data yang atomic (bersifat atomic value). Atom adalah zat terkecil yang masih memiliki sifat induknya, bila terpecah lagi maka ia tidak memiliki sifat induknya.
Syarat normal ke satu (1-NF) antara lain:
1. setiap data dibentuk dalam flat file, data dibentuk dalam satu record demi satu record nilai dari field berupa “atomic value”.
2. tidak ada set atribute yang berulang atau bernilai ganda.
3. telah ditentukannya primary key untuk tabel / relasi tersebut.
4. tiapatribut hanya memiliki satu pengertian.
3. BENTUK NORMAL KE DUA (SECOND NORMAL FORM / 2 NF)
Bentuk normal kedua didasari atas konsep full functional dependency (ketergantungan fungsional sepenuhnya) yang dapat didefinisikan sebagai berikut. Jika A adalah atribut-atribut dari suatu relasi, B dikatakan full functional dependency (memiliki ketergantungan fungsional terhadap A, tetapi tidak secara tepat memiliki ketergantungan fungsional dari subset (himpunan bagian) dari A.
Syarat normal kedua (2-NF) sebagai berikut.
1. Bentuk data telah memenuhi kriteria bentuk normal kesatu.
2. Atribute bukan kunci (non-key) haruslah memiliki ketergantungan fungsionla sepenuhnya (fully functional dependency) pada kunci utama / primary key.
4. BENTUK NORMAL KE TIGA (THIRD NORMAL FORM / 3 NF)
Walaupun relasi 2-NF memiliki redudansi yang lebih sedikit dari pada relasi 1-NF, namun relasi tersebut masih mungkin mengalami kendala bila terjadi anomaly peremajaan (update) terhadap relasi tersebut. Misalkan kita akan melakukan update terhadap nama dari seorang Pemilik (pemilik), seperti Durki (No_Pemilik: CO93), kita harus melakukan update terhadap dua baris dalam relasi Property_Pemilik (lihat Tabel 9.5, (c) relasi Property_Pemilik). Jika kita hanya mengupdate satu baris saja, sementara baris yang lainnya tidak, maka data di dalam database tersebut akan inkonsisten / tidak teratur. Anomaly update ini disebabkan oleh suatu ketergantungan transitif (transitive dependency). Kita harus menghilangkan ketergantungan tersebut dengan melakukan normalisasi ketiga (3-NF).
Syarat normal ketiga (Third Normal Form / 3 NF) sebagai berikut.
1. Bentuk data telah memenuhi kriteria bentuk normal kedua.
2. Atribute bukan kunci (non-key) harus tidak memiliki ketergantungan transitif, dengan kata lain suatu atribut bukan kunci (non_key) tidak boleh memiliki ketergantungan fungsional (functional dependency) terhadap atribut bukan kunci lainnya, seluruh atribut bukan kunci pada suatu relasi hanya memiliki ketergantungan fungsional terhadap priamry key di relasi itu saja.
5. BOYCE-CODD NORMAL FORM (BCNF)
Suatu relasi dalam basis data harus dirancang sedemikian rupa sehingga mereka tidak memiliki ketergantungan sebagian (partial dependecy), maupun ketergantungan transitif (transitive dependecy), seperti telah dibahas pada subbab sebelumnya. Boyce-Codd Normal Form (BCNF) didasari pada beberapa ketergantungan fungsional (functional dependencies) dalam suatu relasi yang melibatkan seluruh candidate key di dalam relasi tersebut. Jika suatu relasi hanya memiliki satu candidate key, maka hasil uji normalisasi sampai ke bentuk normal ketiga sudah identik dengan Boyce-Codd Noormal Form (BCNF).
SOURCE :
https://docs.google.com/viewer?a=v&q=cache:tLKkkSLNgBcJ:mufari.files.wordpress.com/2009/10/normalisasi-database.pdf+normalisasi+database+relasi&hl=id&gl=id&pid=bl&srcid=ADGEEShAn9VvJQinUSnV5OkSuyqkYk8EV8ZdxNy2Yov1UZNBbERBRzbFFHb2Mwsf5LJ_a6xD4PouyIJsY9cUAFzPI5bR4qfH7OPh4IqszPoM9S0OOo5rxCirHFW9_Yval5qG5-oQ-wN&sig=AHIEtbTAt9zlYeZLAvepWerxWZQR_u0QbA
tugas 3
DDL (Data Definition Language )
DDL ( Data Definition Language ) adalah sebuah perintah SQL yang berhubungan dengan pendefinisian suatu database dan tabel. Beberapa perintah dasar yang termasuk dalam DDL antara lain.
1. CREATE
Fungsi : Command CREATE ini berfungsi untuk membuat sebuah database ataupun membuat sebuah table yang berada di dalam database.
Syntax : CREATE database nama_database;
Parameter : -
Contoh : CREATE database apotik;
Penjelasan : perintah CREATE diatas akan membuat sebuah database dengan nama apotik.
2. SHOW
Fungsi : Command SHOW ini berfungsi untuk menampilkan database ataupun table yang telah kita buat sebelumnya.
Syntax : SHOW databases;
Parameter : -
Contoh : SHOW databases;
Penjelasan : perintah SHOW diatas akan memperlihatkan semua database yang ada.
3. USE
Fungsi : Command USE ini berfungsi untuk membuka/mengaktifkan/memasuki database yang telah kita buat. Setelah kita masuk kedalam database yang telah kita buat, barulah kita bisa memanipulasi data yang ada, termasuk untuk membuat table didalam database tersebut.
Syntax : USE nama_database;
Parameter : -
Contoh : USE apotik;
penjelasan : perintah diatas akan mengaktifkan database dengan nama apotik sehingga kita dapat memanipulasi data yang ada.
4. ALTER
Fungsi : Command ALTER ini berfungsi untuk mengubah struktur dari suatu table. Mengubah disini tidak hanya memperbaharui struktur table yang ada, tetapi juga mengubah nama field, menambahkan primary key, mengubah tipe field, maupun menghapus field yang telah dibuat sebelumnya.
Syntax : ALTER TABLE nama_tabel parameter_option;
Parameter : add, modify, drop
Contoh : ALTER TABLE obat ADD harga int (6);
Penjelasan : perintah diatas akan menambahkan field harga kedalam tabel obat.
5. DROP
Fungsi: Command DROP ini berfungsi untuk menghapus, baik database, table, maupun field yang telah diinputkan ke dalam table.
Syntax : DROP TABLE nama_tabel;
Parameter : -
Contoh : DROP TABLE supplier;
Penjelasan : perintah diatas akan menghapus tabel supplier pada database apotik.
Data Manipulation Language (DML)
Data Manipulation Language (DML) digunakan dalam memanipulasi dan pengambilan data pada database.
Manipulasi data, dapat mencakup:
1.Pemanggilan data yang tersimpan dalam database (query).
2.Penyisipan/penambahan data baru ke database.
3.Penghapusan data dari database.
4.Pengubahan data pada database.
Beberapa perintah dasar yang termasuk dalam DDL antara lain.
1. SELECT
Fungsi : Command SELECT ini berfungsi untuk menampilkan sesuatu. Menampilkan disini tidak hanya menampilkan data dari sebuah table saja, tetapi juga untuk menampilkan suatu ekspresi. Seperti menampilkan hanya field yang memiliki kategori Suplement saja.
Syntax : SELECT * FROM nama_tabel;
Parameter : from, order by, where, dll
Contoh : SELECT * FROM obat;
Penjelasan : perintah diatas akan menampilkan semua isi pada tabel obat.
2. DESC
Fungsi : Command DESC ini berfungsi untuk menampilkan struktur tabel yang telah dibuat. Apa saja field yang telah dibuat, type data dari field tersebut, dan primary key akan terlihat disini.
Syntax : DESC nama_table;
Parameter : -
Contoh : DESC obat;
Penjelasan : perintah diatas akan memperlihatkan stuktur dari tabel obat yang telah dibuat.
3. INSERT INTO
Fungsi : Command INSERT INTO ini berfungsi untuk menambahkan data/record dalam suatu tabel yang telah dibuat.
Syntax : INSERT INTO nama_tabel VALUES (‘isi_field1’ , ‘isi_field2’,……);
Parameter : values, set
Contoh : INSERT INTO obat VALUES (’CO012’,’Corsel’,’Suplement’,’13’,’183500’);
Penjelasan : perintah diatas akan membuat sebuah record baru dalam tabel obat dengan id_obat = CO012, nama_obat = Corsel, kategori = Suplement, jumlah = 13, dan harga = 183500.
4. UPDATE
Fungsi : Command UPDATE ini berfungsi untuk merubah/memperbaharui data yang telah ada di dalam tebel.
Syntax : UPDATE nama_tabel SET nama_field = ’nilai_baru’ WHERE nama_field = ’kondisi’ ;
Parameter : set, where
Contoh : UPDATE obat SET id_obat = ‘CE008’ WHERE nama_obat = ‘Cetoros’;
Penjelasan : perintah diatas akan mengubah id_obat BD019 menjadi CE008 pada tabel obat yang memiliki nama_obat Cetoros.
5. DELETE FROM
Fungsi : Command DELETE FROM ini berfungsi untuk menghapus record yang ada pada sebuah tabel.
Syntax : DELETE FROM nama_tabel WHERE nama_field =’option’;
Parameter : where
Contoh : DELETE FROM obat WHERE id_obat =’CO012’;
Penjelasan : perintah diatas akan menghapus record dari tabel obat yang memiliki id_obat CO012.
6. EXPLAIN
Fungsi : Command EXPLAIN ini memiliki fungsi yang sama seperti Desc yaitu berfungsi untuk menampilkan struktur tabel yang telah dibuat, seperti nama_field, type data dari field tersebut, dan primary key.
Syntax : EXPLAIN nama_table;
Parameter : -
Contoh : EXPLAIN obat;
Penjelasan : perintah diatas akan memperlihatkan stuktur dari tabel obat yang telah dibuat.
7. SELECT DESCENDING
Fungsi : Command SELECT DESCENDING ini berfungsi menampilkan semua data dari bawah ke atas berdasarkan field yang telah ditentukan.
Syntax : SELECT field1, field2, dan seterusnya FROM nama_tabel ORDER BY field yang jadi acuan DESC;
Parameter : from, order by, desc
Contoh : SELECT id_obat, nama_obat, jumlah FROM BY obat ORDER BY id_obat DESC;
Penjelasan : Perintah diatas akan menampilkan data pada id_obat, nama_obat dan jumlah pada tabel obat dan yang menjadi acuan pengurutan data dari bawah ke atas adalah id_obat.
8. SELECT COUNT
Fungsi : Command SELECT COUNT ini berfungsi menampilkan jumlah record yang ada dalam suatu tabel.
Syntax : SELECT COUNT(*)FROM nama_tabel;
Parameter : count, from
Contoh : SELECT COUNT(*)FROM obat;
Penjelasan : Perintah diatas menampilkan jumlah record yang ada pada tabel obat.
9. SELECT MAX
Fungsi : Command SELECT MAX ini berfungsi untuk mencari nilai tertinggi pada sebuah field di tabel.
Syntax : SELECT MAX(nama_field) FROM nama_tabel;
Parameter : max, from
Contoh : SELECT MAX(jumlah) FROM obat;
Penjelasan : Perintah diatas akan menampilkan nilai tertinggi dari field jumlah pada tabel obat.
10. SELECT MIN
Fungsi : Command SELECT MIN ini berfungsi untuk mencari nilai terendah pada sebuah field di tabel.
Syntax : SELECT MIN(nama_field) FROM nama_tabel;
Parameter : min, from
Contoh : SELECT MIN(jumlah) FROM obat;
Penjelasan : Perintah diatas akan menampilkan nilai terendah dari field jumlah pada tabel obat.
DCL atau Data Control Language
DCL atau Data Control Language
DCL merupakan perintah SQL yang berhubungan dengan pengaturan hak akses user MySQL, baik terhadap server, database, tabel maupun field. Perintah SQL yang termasuk dalam DCL antara lain :
1. GRANT : Perintah ini digunakan untuk memberikan hak / izin akses oleh administrator (pemilik utama) server kepada user (pengguna biasa). Hak akses tersebut berupa hak membuat (CREATE), mengambil (SELECT), menghapsu (DELETE), mengubah (UPDATE) dan hak khusus berkenaan dengan sistem databasenya.
SINTAKS : GRANT privileges ON tbname TO user
CONTOH : grant select, update, insert, delete on perpustakaan.buku to 'ali'@'localhost';
2. REVOKE : perintah ini memiliki kegunaan terbalik dengan GRAND, yaitu untuk menghilangkan atau mencabut hak akses yang telah diberikan kepada user oleh administrator.
SINTAKS : REVOKE privileges ON tbname FROM user
CONTOH : revoke select, update, insert, delete on perpustakaan.buku from 'ali'@'localhost';
DQL (Data Query Language)
Berikuti ini contoh Query dalam SQL untuk select sederhana,
$data_user = "SELECT * FROM user";
artinya untuk mengambil semua field data pada table user. Dalam Query Doctrine kita bisa menuliskan seperti berikut ini,
$this->data_user = Doctrine::getTable('User')->findAll();
Perhatikan susunan penulisannya. Ada getTable dan element yang mau dicari adalah semua, findAll. Perubahan mendasar dalam penulisan script SQL adalah menggunakan method dengan penamaan yang lebih “manusiawi”. Kalau di SQL biasa dengan tanda bintang asterik “*“, kalau di Doctrine menggunakan method findAll(). Kalau di SQL memanggil nama table nya (misal. user), kalau di Doctrine memanggil nama Model nya (misal. User). Dalam Doctrine (symfony), penulisan nama Model selalu di awali huruf besar, jadi agak sedikit berbeda dengan nama table di database nya.
*Perhatikan susunan penulisannya, karena kita akan sering menemui hal-hal seperti itu nantinya..
Query Select untuk Primary Key tertentu
Percobaan selanjutnya kita akan menggunakan Query select sederhana untuk mengambil data dengan Primary Key tertentu. Misal Table user memiliki primary key pada field id, dan kita akan menampilkan data yang id nya ’1′. maka SQL nya adalah seperti berikut ini,
$data_user = "SELECT * FROM user WHERE (id = '1')";
Maka dalam Query Doctrine kita dapat menuliskan seperti ini,
$this->data_user = Doctrine::getTable('User')->find(1);
Method find() dalam Doctrine digunakan untuk menemukan record berdasarkan primary key nya. Dalam kasus ini, kita tidak perlu memberi tahu Doctrine “siapa yang menjadi primary key“. Pokok nya kalau kita gunakan method find(), maka pasti akan mencari untuk primary key nya saja, yaitu field id.
Query Select mencari field tertentu
Dan ini yang lebih menarik lagi. Yaitu jika kita ingin mencari data dengan syarat field tertentu. Misal, saya ingin mencari record yang field ‘name’ pada table tersebut berisi ‘sule’. Dalam SQL kita biasa menuliskan seperti ini,
$data_user = "SELECT * FROM user u WHERE (u.name = 'sule')";
pada contoh diatas kita menggunakan alias ‘u‘ untuk table user, dan kemudian menambahkan syarat bahwa field name harus terisi oleh ‘sule‘. Dalam Doctrine, penulisannya semakin mudah.
$this->data_user = Doctrine::getTable('User')->findByName('sule');
Gunakan method findBy… yg penulisannya ditambahkan dengan nama field yang akan kita cari. Dalam contoh diatas field yang akan dicari ada lah field ‘name‘, maka method yang digunakan findByName(). Perhatikan penulisan huruf besar kecil, sebagai penanda kata.
Query Select dengan beragam Syarat
Tingkatan lebih lanjut, kita akan mencoba melakukan Query untuk beragam syarat. Seperti yang telah Anda ketahui, syarat dalam Query dapat kita gunakana dengan menambahkan “WHERE“. Untuk referensi nya dapat dilihat di dokumen symfony tentang query.
Berikut ini contoh pengunaan syarat yang lumayan kompleks,
$this->data_user = Doctrine_Query::create()
->from('User u')
->where('u.name = "sule" ')
->execute();atau bisa dengan cara ini,
$this->data_user = Doctrine_Core::getTable('User')
-createQuery('u')
->where('u.name = "sule" ')
->execute();atau dengan cara ini juga bisa,
$this->data_user = Doctrine::getTable('User')
->createQuery('u')
->where('u.name = "sule" '
->execute();Ketiga cara diatas adalah sama, akan menghasilkan Query seperti ini,
$data_user = "SELECT * FROM user u WHERE (u.name = "sule")";
Jadi jangan bingung dengan penggunaan syntax Doctrine, karena akan ada banyak cara menggunakannya, tergantung kebutuhan.
Tugas 2
Tipe Data DBMS
1. MySQL :
- DATETIME : Sebuah kombinasi dari waktu (jam) dan tanggal. MySQL menampilkan waktu dan tanggal dalam format 'YYYY-MM-DD HH:MM:SS'. Jangkauan nilainya adalah '1000-01-01 00:00:00' hingga '9999-12-31 23:59:59'.
- CHAR(M) [BINARY] : String yang memiliki lebar tetap. Nilai M adalah dari 1 hingga 255 karakter. Jika ada sisa, maka sisa tersebut diisi dengan spasi (misalnya nilai M adalah 10, tapi data yang disimpan hanya memiliki 7 karakter, maka 3 karakter sisanya diisi dengan spasi). Spasi ini akan dihilangkan apabila data dipanggil. Nilai dari CHAR akan disortir dan diperbandingkan secara case-insensitive menurut default character set yang tersedia, kecuali bila atribut BINARY disertakan.
- VARCHAR(M) [BINARY] : String dengan lebar bervariasi. Nilai M adalah dari 1 hingga 255 karakter. Jika nilai M adalah 10 sedangkan data yang disimpan hanya terdiri dari 5 karakter, maka lebar data tersebut hanya 5 karakter saja, tidak ada tambahan spasi.
- BLOB dan TEXT : Sebuah BLOB atau TEXT dengan lebar maksimum 65535 (2^16 - 1) karakter.
- ENUM('value1','value2',...) : Sebuah enumerasi, yaitu objek string yang hanya dapat memiliki sebuah nilai, dipilih dari daftar nilai 'value1', 'value2', ..., NULL atau nilai special "" error. Sebuah ENUM maksimum dapat memiliki 65535 jenis nilai
2. ORACLE :
- VARCHAR2(size)
Untuk menampung string/karakter dengan panjang bervariasi (tidak harus sepanjang saat didefinisikan). Ukuran maksimum 4000. - NVARCHAR2(size)
Untuk menampung string/karakter dengan panjang bervariasi (tidak harus sepanjang saat didefinisikan). Ukuran maksimum 4000, tergantung dari karakter nasional yang dipakai dalam database. - CHAR(size)
Untuk menyimpan string/karakter dengan panjang tetap, maksimum panjangnya 2000, defaultnya 1 byte dan akan dimampatkan di sebelah kanan sampai panjang terpenuhi dengan memakai spasi. - INTERVAL YEAR(precision) TO MONTH
Waktu dalam bentuk tahun dan bulan, dimana precision adalah digit dari tahun yang digunakan (mulai 0-9, default 2). - UROWID(size)
String basis 64 yang merepresentasi alamat unik tiap baris dalam tabel yang terindex, ukuran maksimumnya 4000 byte.
3. PostgreSQL :
- Karakter Jenis
SQL mendefinisikan dua jenis karakter utama: karakter yang bervariasi (n) dan karakter (n), dimana n adalah bilangan bulat positif. Kedua jenis dapat menyimpan string hingga karakter n (tidak bytes) panjangnya. Sebuah usaha untuk menyimpan string lagi ke dalam kolom jenis akan menghasilkan kesalahan, kecuali kelebihan karakter semua ruang, dalam hal ini string akan dipotong dengan panjang maksimum. (. Ini kecuali agak aneh diperlukan oleh standar SQL) Jika string untuk disimpan lebih pendek dari panjang menyatakan, nilai-nilai karakter jenis akan ruang-empuk, nilai-nilai yang bervariasi tipe karakter hanya akan menyimpan string pendek. - boolean Type
PostgreSQL menyediakan boolean SQL tipe standar. boolean dapat memiliki salah satu dari hanya dua negara: "true" atau "false ". Sebuah negara ketiga, "tidak diketahui", diwakili oleh nilai null SQL. - UUID TypeUuid tipe data menyimpan Universally Unique Identifier (UUID) seperti yang didefinisikan oleh RFC 4122, ISO / IEC 9834-8:2005, dan standar terkait. (Beberapa sistem mengacu pada tipe data ini sebagai pengenal global yang unik, atau GUID, sebagai gantinya.) Identifier ini adalah kuantitas 128-bit yang dihasilkan oleh algoritma dipilih untuk membuatnya sangat mungkin bahwa identifier yang sama akan dihasilkan oleh orang lain di alam semesta yang dikenal dengan menggunakan algoritma yang sama. Oleh karena itu, untuk sistem terdistribusi, pengidentifikasi ini memberikan jaminan keunikan baik dari generator urutan, yang hanya unik dalam database tunggal.
- Biner Tipe Data
Jenis bytea data memungkinkan penyimpanan string biner, lihat Tabel 8-6.
Tabel 8-6. Biner Tipe Data, Nama Penyimpanan Ukuran Deskripsi,bytea 1 atau 4 bytes ditambah string biner yang sebenarnya variabel-panjang string biner. Sebuah string biner adalah urutan oktet (atau byte). String biner dibedakan dari string karakter dalam dua cara: Pertama, string biner khusus memungkinkan oktet menyimpan nilai nol dan lainnya "non-printable" octets (biasanya, oktet luar kisaran 32-126). Karakter string melarang nol oktet, dan juga melarang setiap nilai oktet lainnya dan urutan nilai oktet yang valid sesuai dengan encoding set yang dipilih dalam database karakter. Kedua, operasi pada string biner memproses byte yang sebenarnya, sedangkan pengolahan string karakter tergantung pada pengaturan lokal. Singkatnya, string biner yang tepat untuk menyimpan data yang programmer berpikir sebagai "byte mentah", sedangkan string karakter yang sesuai untuk menyimpan teks. - Numerik
jenis numerik dapat menyimpan nomor dengan sampai 1000 digit resisi dan melakukan perhitungan dengan tepat. hal ini terutama dianjurkan untuk menyimpan sejumlah uang dan jumlah lain dimana ketepatan diperlukan. namun, aritmatika pada nilai-nilai numerik yang sangat lambat dibandingkan dengan tipe integer, atau ke tipe floating-point yang dijelaskan dibagian selanjutnya.
4. DB2
o Relation
Relationship antara entiti merupakan ekuivalensi dalam database pada sebuah pernyataan. Sebuah pengiriman beberapa “Parts” mensyaratkan bahwa “Supplier” harus terdaftar sebagai “Supplier”. Relationships dalam database akan muncul sebagai relasi “foreign key” antara 2(dua) tabel atau akan muncul sebagai sebuah tabel yang terpisah.
Relationships didalam sebuah database menjaberkan aturan hubungan antar entiti yang berelasi. Jika setiap pengiriman “Parts” harus dikirim oleh Supplier yang terdaftar maka dapat kita buat relasi many-to-one antara “Shipments” dan “Supplier”. Domain merupakan alias dari “built-in data types”, termasuk presisi dan range nilai/value yang dapat kita masukkan. Beberapa domain, misalkan tipe data boolean, merupakan pre-defined data types pada Adaptive Server Anywhere, dimana presisi nilainya 1 dan range nilainya 1(benar) atau 0(Salah), kita juga dapat menambahkan domain sesuai kebutuhan kita.
o Candidate Key
Candidate key merupakan satu attribut atau kombinasi satu attribut atau lebih yang secara unik menjadi identifier pada suatu relasi. Candidate Key ini harus memenudi syarat sebagai berikut :
1 Unique identifier, untuk setiap row/tuple candidate key harus secara unik dapat menjadi identifier. Artinya setiap non candidate key attibute secara fungsional bergantung pada candidate key tersebut.
2 Non Redudancy, Tidak ada duplikasi candidare key untuk menjadi uniqe indentifier, dimana tidak dapat dilakukan penghapusan pada candidate key dimana tidak merusak sifat unique identifier.
o WORKGROUP Server Edition
Versi ini merupakan DBMS untuk multi User, client/server yang didesign untuk komputer yang memiliki hingga 4 CPU dan memory hingga 16GB dan memiliki sistem operasi linux, windows, solaris, linux, AIX dll. memiliki fitur yang sama dengan DB2 Express namun dengan skala yang lebih besar.
o DB2 Express-C : Versi ini merupakan entry level data server yang didesign untuk komputer yang memiliki hingga 2 CPU dan memory hingga 4GB dan memiliki sistem operasi Linux, atau Windows. Versi ini dapat digunakan untuk tujuan evaluasi dan dapat digunakan secara gratis.
o DB2 Personal Edition : Merupakan DBMS untuk single user yang ideal untuk desktop ataupun laptop. Dapat digunakan untuk create, modifikasi dan mengatur banyak database lokal.