
tugas 6
Relasi Table pada Mysql
Menggunakan Keluarga Join
Relasi table pada database sangat diperlukan untuk menyederhanakan data-data kita,dan supaya mudah untuk diatur.Ada beberapa cara yang digunakan untuk merelasikan table.Pada pelajaran kali ini saya akan mengajarkan cara relasi database dengan menggunakan keluarga JOIN.Relasi table dengan Join ada 6 macam.
CROSS JOINSTRAIGHT JOININNER JOINRIGHT JOINLEFT JOINNATURAL JOIN
Sebelum memulai pelajaran kali ini saya asumsikan di computer anda sudah terinstal mysql
server,dan phpmyadmin.Jika anda belum punya silahkan download disini untuk phpmyadmin
http://www.phpmyadmin.net/home_page/downloads.php dan untuk mysql download disini
http://www.mysql.com/downloads/mysql/ atau agar lebih mudah download aja yang sudah
dipaket,anda bias gunakan wamp download disini http://www.wampserver.com/en/ .
Untuk mempermudah pelajaran kali ini saya sudah menyiapakan database yang sudah saya
export dengan nama produk.sql.silahkan di import melalui phpmyadmin.dan juga saya sudah
siapkan versi dump nya.
Note:Cocokan versi mysql dump anda dengan dump yang saya gunakan kalau tidak database
tidak bias di import.
Note:Query Mysql bersifat case-insensitif sehingga perbedaan huruf kecil dan besar tidak
masalah.tetapi untuk nama table,nama database,record,nama_field tidak berlaku.
Contoh:
Anda membuat table namanya nilai dengan huruf kecil semua.untuk menampilkan isi dari table
gunakan query berikut
select * from nilai //work
select * from Nilai //don’t work
select * from NILAI //don’t work
SeLeCt * FroM nilai //work
Ok sekarang masuk dulu ke mysql server anda kalau pakai console ketik mysql –u root –p
[enter] masukkan password.
Setelah itu masuk ke database produk
mysql> use produk
Lalu untuk melihat table yang sudah dibuat ketik perintah berikut
mysql> show tables;
+------------------+
| Tables_in_produk |
+------------------+
| jenis |
| produk |
+------------------+
2 rows in set (0.00 sec)
Disitu terdapat dua table yang ingin kita relasikan yaitu table jenis dan produk.Untuk meliat
deskripsi dari kedua table tersebut gunakan query berikut:
mysql> desc produk;
+-----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+----------------+
| id_produk | int(11) | NO | PRI | NULL | auto_increment |
| nm_produk | varchar(40) | YES | | NULL | |
| no_jenis | int(3) | YES | | NULL | |
+-----------+-------------+------+-----+---------+----------------+
3 rows in set (0.01 sec)
mysql> desc jenis
-> ;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| no_jenis | int(11) | NO | PRI | NULL | auto_increment |
| nm_jenis | varchar(20) | YES | | NULL | |
+----------+-------------+------+-----+---------+----------------+
2 rows in set (0.01 sec)
Ok sekarang kita perhatikan pada table jenis dan produk terdapat field yang sama yaitu
no_jenis.yang akan kita gunakan untuk merelasikan kedua table berikut.
Pada table produk primary key nya adalah id_produk sedangkan pada table jenis primary key
nya adalah no_jenis.Nah,pada table jenis no_jenis adalah kunci primer(primary key),sedangkan
pada table produk no_jenis adalah kunci tamu(foreign key).
Sekarang kita lihat isi dari masing-masing table berikut
mysql> select * from jenis;
+----------+------------+
| no_jenis | nm_jenis |
+----------+------------+
| 1 | Furniture |
| 2 | Elektronik |
| 3 | FOOD |
+----------+------------+
3 rows in set (0.00 sec)
mysql> select * from produk;
+-----------+-----------+----------+
| id_produk | nm_produk | no_jenis |
+-----------+-----------+----------+
| 1 | Lemari | 1 |
| 2 | Kulkas | 2 |
| 3 | Meja | 1 |
| 4 | Bangku | 1 |
| 5 | Televisi | 2 |
| 6 | Komputer | 2 |
+-----------+-----------+----------+
6 rows in set (0.00 sec)
Nah pada field/kolom no_jenis pada table jenis dan produk ,kita bermaksud menghubungkan no_jenis di table jenis dan no_jenis di table produk,agar angka-angka di field no_jenis pada
table produk diganti dengan huruf pada field nm_jenis di table jenis.kita bias melakukan hal
tersebut dengan merelasi kan kedua table tersebut.
Query Relasi : select nama_table1.nama_kolom1,nama_table2.nama_kolom2
…. nama_table(n).nama_kolom(n) from nama_table1,nama_table2..nama_table(n)
Artikel Populer IlmuKomputer.Com
Copyright ©2003- 2006 IlmuKomputer.Com
tugas 5
NORMALISASI DATABASE
ketika kita merancang suatu basis data untuk suatu sistem relational, prioritas utama dalam mengembangkan model data logical adalah dengan merancang suatu representasi data yang tepat bagi relationship dan constrainnya (batasannya). Kita harus mengidentifikasi suatu set relasi yang cocok, demi mencapai tujuan di atas. Tehnik yang dapat kita gunakan untuk membantu mengidetifikasi relasi-relasi tersebut dianamakan Normalisasi. Proses normalisasi pertama kali diperkenalkan oleh E.F.Codd pada tahun 1972. normalisasi sering dilakukan sebagai suatu uji coba pada suatu relasi secara berkelanjutan untuk menentukan apakah relasi tersebut sudah baik atau masih melanggar aturan-aturan standar yang diperlakukan pada suatu relasi yang normal (sudah dapat dilakukan proses insert, update, delete, dan modify pada satu atau beberapa atribut tanpa mempengaruhi integritas data dalam relasi tersebut). Proses normalisasi merupakan metode yang formal/standar dalam mengidentifikasi dasar relasi bagi primary keynya (atau candidate key dalam kasus BCNF), dan dependensi fungsional diantara atribut-atribut dari relasi tersebut. Normalisasi akan membantu perancang basis data dengan menyediakan suatu uji coba yang berurut yang dapat diimplementasikan pada hubungnan individualshingga skema relasi dapat di normalisasi ke dalam bentuk yang lebih spesifik untuk menghindari terjadinya error atau inkonsistansi data, bila dilakuan update tehadap relasi tersebut dengan Anomaly.
BEBERAPA DEFINISI NORMALISASI
- Normalisasi adalah suatu proses memperbaiki / membangun dengan model data relasional, dan secara umum lebih tepat dikoneksikan dengan model data logika.
- Normalisasi adalah proses pengelompokan data ke dalam bentuk tabel atau relasi atau file untuk menyatakan entitas dan hubungan mereka sehingga terwujud satu bentuk database yang mudah untuk dimodifikasi.
- Normalisasi dapat berguna dalam menjawab 2 pertanyaan mendasar yaitu: “apa yang dimaksud dengan desain database logical?” dan “apa yang dimaksud dengan desain database fisikal yang baik? What is phisical good logical database design?”.
- Normalisasi adalah suatu proses untuk mengidentifikasi “tabel” kelompok atribut yang memiliki ketergantungan yang sangat tinggi antara satu atribut dengan atrubut lainnya.
- Normalisasi bisa disebut jga sebagai proses pengelompokan atribut-atribut dari suatu relasi sehingga membentuk WELL STRUCTURED RELATION.
WELL STRUCTURED RELATION adalah sebuah relasi yang jumlah kerangkapan datanya sedikit (Minimum Amount Of Redundancy), serta memberikan kemungkinan bagi used untuk melakukan INSERT, DELETE, MODIFY, terhadap baris-baris data pada relasi tersebut, yang tidak berakibat terjadinya ERROR atau INKONSISTENSI DATA, yang disebabkan oleh operasi-operasi tersebut.
Langkah-Langkah Normalisasi
1. Bentuk Normal Pertama (1NF)
Sebuah model data dikatakan memenuhi bentuk normal pertama apabila setiap atribut yang dimilikinya memiliki satu dan hanya satu nilai. Apabila ada atribut yang memiliki nilai lebih dari satu, atribut tersebut adalah kandidat untuk menjadi entitas tersendiri.
Entitas utama untuk database tugas matakuliah tentu saja Tugas Matakuliah.
GAMBAR
Entitas pertama dalam contoh model data untuk database tugas matakuliah. Atribut Nama Kelas mencantumkan kelas-kelas di mana tugas tersebut berlaku. Apabila Pendaftar untuk sebuah matakuliah melebihi kapasitas ruangan yang dimiliki fakultas, kebijakan yang umum diambil Kepala Program Studi adalah membagi kegiatan perkuliahan untuk matakuliah tersebut menjadi beberapa kelas. Karenanya atribut ini rentan memiliki nilai jamak, dan lebih sesuai menjadi entitas baru atau atribut dari entitas lain. Untuk sementara kita membuat entitas baru, Kelas, dimana sebagian atributnya berasal dari Tugas Matakuliah yang secara logis lebih sesuai menjadi atribut entitas ini. Sementara itu, hampir semua atribut entitas Tugas Matakuliah selain Nama Kelas memiliki nilai tunggal (dengan asumsi setiap matakuliah dihampu oleh satu dosen saja).
- Relasi Antar-Entitas dan Identifier
Masalah yang kita hadapi sekarang adalah menghubungkan Tugas Matakuliah dengan Kelas. Satu tugas dapat diberikan pada beberapa kelas yang berbeda; dalam terminologi pemodelan data, ini berarti antara entitas Tugas Matakuliah dan entitas Kelas terdapat relasi 1:N (atau 1-N) untuk nilai N lebih dari satu. Cara paling intuitif untuk menghubungkan kedua entitas tersebut adalah menyertakan identitas satu entitas sebagai atribut entitas lain. Identitas sebuah entitas haruslah unik untuk menghindarkan ambiguitas saat akan merujuk pada satu objek khusus dari entitas tersebut. Entitas Tugas Matakuliah akan menggunakan pengidentifikasi arbitrer berupa angka yang berbeda antara satu objek Tugas Matakuliah dengan objek Tugas Matakuliah lain. Entitas Kelas dapat diidentifikasi dengan matakuliah dan kode kelas yang bersangkutan, sehingga kita cukup menambahkan atribut pengidentifikasi (identifier) dalam kedua entitas. Entitas ini beserta semua atribut baru dan hubungannya dengan Tugas Matakuliah diperlihatkan
dalam Gambar di bawah ini, dengan menggunakan notasi relasi crows foot (dengan simbol “kaki gagak” menunjuk pada entitas jamak). Hubungan antara Tugas Matakuliah dan entitas baru, Kelas. Sejauh ini tidak ada atribut entitas yang memiliki nilai lebih dari satu, sehingga rasanya cukup aman mengatakan bahwa model ini memenuhi bentuk normal pertama.
2. Bentuk Normal Kedua (2NF)
Sebuah model data dikatakan memenuhi bentuk normal kedua apabila ia memenuhi bentuk normal pertama dan setiap atribut non-identifier sebuah entitas bergantung sepenuhnya hanya pada semua identifier entitas tersebut.
Apabila kita perhatikan kembali model data yang telah kita hasilkan di atas, segera terlihat bahwa atribut dari entitas Kelas tidak sepenuhnya bergantung pada identitas unik Kelas tersebut. Seorang dosen akan tetap ada meskipun kelas matakuliah yang ia ampu sudah tidak ada lagi. Dalam hal ini, dosen adalah entitas tersendiri (yang nantinya dapat dilekatkan pada entitas Fakultas atau Universitas bilamana kedua entitas tersebut dirasa perlu ada, tergantung pada kebutuhan pemodelan data kita).
- Sekali Lagi, Tentang Identifier
Dalam dunia nyata, anggapan yang umum adalah seseorang (“individu”) dapat diidentifikasi secara unik dengan namanya. Tentu saja anggapan ini tidak sepenuhnya benar, karena bisa saja sebuah nama (bahkan satu rangkaian nama lengkap) dimiliki oleh lebih dari satu orang; pemodelan data yang melibatkan informasi tentang individu jarang menggunakan nama individu tersebut sebagai satu-satunya pengidentifikasi. Implementasi RDBMS tertentu juga akan lebih cepat memproses query atas suatu tabel apabila tabel tersebut diindeks oleh nilai
integer unik daripada bila menggunakan indeks karakter (rangkaian karakter masih harus diumpankan ke fungsi hash agar dapat digunakan sebagai indeks tabel, sementara untuk integer unik tidak harus).
Karena beberapa alasan tersebut, entitas Dosen pada model data kita akan menggunakan pengidentifikasi arbitrer berupa Nomor Induk Pegawai sebagaimana diperlihatkan gambar dibawah ini. Dalam notasi crows foot, relasi non-identifying digambarkan dengan garis putusputus atau tersamar.
GAMBAR
Ketiga entitas utama dalam model data dan hubungan antar masing-masing entitas. Setelah atribut-atribut dari semua entitas dalam sebuah model data hanya bergantung pada seluruh pengidentifikasi entitas yang memilikinya, model data tersebut dikatakan memenuhi bentuk normal kedua.
3. Bentuk Normal Ketiga (3NF)
Sebuah model data dikatakan memenuhi bentuk normal ketiga apabila ia memenuhi bentuk normal kedua dan tidak ada satupun atribut non-identifying (bukan pengidentifikasi unik) yang bergantung pada atribut non-identifying lain. Apabila ada, pisahkan salah satu atribut tersebut menjadi entitas baru, dan atribut yang bergantung padanya menjadi atribut entitas baru tersebut.
Dalam model data sederhana yang kita gunakan di sini, tidak ada satupun atribut non-identifying (seperti Deskripsi Tugas Matakuliah, atau Nama Dosen) yang bergantung pada atribut nonidentifying lain. Namun demi adanya contoh, kita misalkan entitas Dosen memiliki atribut informasi Alamat Rumah dan Nomor Telepon Rumah. Keduanya tidak dapat secara unik mengidentifikasi objek tertentu dari entitas Dosen, namun keduanya saling bergantung. Sebagaimana dalam dua langkah normalisasi sebelumnya, jenis kebergantungan seperti ini dapat dihilangkan dengan membuat entitas baru lagi (yang tidak akan diciptakan karena tiga entitas sudah cukup banyak untuk satu artikel).
Model terakhir yang kita dapat ini telah memenuhi bentuk normal ketiga (third normal form) dan siap dikonversi menjadi tabel. Namun sebelumnya, kita perlu membahas berbagai jenis relasi yang kerap ditemui dalam pemodelan data, termasuk yang kita temui dalam contoh model data kali ini.
Artikel Populer IlmuKomputer.Com
Copyright ©2003- 2006 IlmuKomputer.Com
tugas 4
Diagram Entity-Relationship (Diagram E-R)
Model ER berisi komponen-komponen Himpunan Entitas dan Himpunan Relasi yang masing-masing dilengkapi dengan atribut-atribut yang merepresentasikan seluruh fakta dari ‘dunia nyata’ yang kita tinjau. Digambarkan dengan lebih sistematis dengan menggunakan Diagram Entity-Relationship (Diagram E-R). Dikembangkan oleh Chen (1976).
KOMPONEN-KOMPONEN DIAGRAM E-R
TUGAS 3
CONTOH DDL, DML, DQL, DAN DCL DALAM SISTEM BASIS DATA
Structured Query Language (SQL)
Sturctured Query Language digunakan untuk berkomunikasi dengan database. Berdasarkan ANSI (American National Standards Institute) SQL menjadi bahasa standart untuk berhubungan dengan DBMS. Perintah - perintah SQL digunakan untuk berbagai macam tujuan seperti merubah data, menghapus data atau menambah data pada database. Banyak DBMS yang menggunakan perintah - perintah SQL diantaranya adalah Oracle, Sybase, Ingres, MySQL dan lain - lain.1.
Data Definition Language ( DDL )
DDL mendefinisikan struktur basis data, seperti pembuatan basis data, pembuatan tabel dsbnya. Contoh: CREATE DATABASE dan CREATE TABLE.
- Perintah SQL untuk definisi data:
• CREATE untuk membentuk basis data, table atau index
• ALTER untuk mengubah struktur table
• DROP untuk menghapus basis data, table atau index
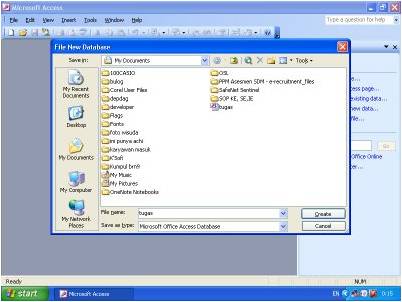
Contoh create database

Contoh create tabel
Data Manipulation Languange ( DML )
DML merupakan bagian untuk memanipulasi basis data seperti: pengaksesan data, penghapusan, penambahan dan pengubahan data. DML juga dapat digunakan untuk melakukan komputasi data. Contoh: INSERT,DELETE, dan UPDATE.
- Bahasa untuk mengakses basis data
- Bahasa untuk mengolah basis data
- Bahasa untuk memanggil fungsi-fungsi agregasi
- Bahasa untuk melakukan query
- Jenis-jenis query:
• Sederhana
• Join
• Bertingkat ( Nested Query )
Contoh : Skema Model Relasi Antar Tabel Rental DVD
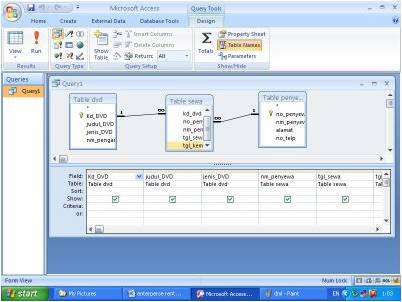
Contoh create query
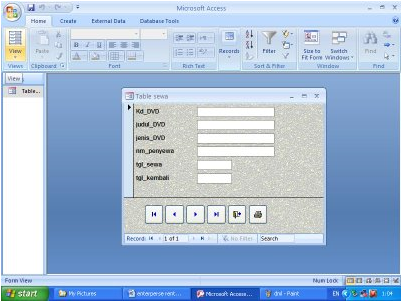
Contoh form
Structured Query Language (SQL)
Structured Query Language (SQL) pertama kali dikembangkan pada akhir tahun 1970-an di Laboratorium IBM San Jose, California. SQL adalah bahasa standard untuk melakukan berbagai operasi data pada database, diantaranya mendefinisikan tabel, menampilkan data dengan kriteria tertentu, menambahkan data hingga menghapus data tertentu.
Beberapa perintah SQL yang akan dibahas pada laporan ini, yaitu
INSERT : digunakan untuk memasukkan data ke dalam tabel.
- · SELECT, digunakan untuk menampilkan data.
- · FROM, digunakan untuk menunjukkan dari relasi mana data yang akan difilter.
- · WHERE, digunakan untuk membuat suatu kondisi.
DELETE : digunakan untuk menghapus data pada sebuah tabel. UPDATE : digunakan untuk mengubah data pada suatu tabel dengan kriteria Tertentu. ORDER BY : digunakan untuk menampilkan data dengan urutan menaik (ASC) atau urutan menurun (DESC). Penggunaan SQL pada beberapa bahasa pemrograman secara umum relatif sama. Berikut akan dijelaskan beberapa perintah SQL yang sering digunakan dalam operasi pemrograman database.
Langkah Kerja
- Membuat tabel mahsiswa, jurusan dan fakultas Dengan cara : CREATE TABLE [NAMA TABEL] ([NAMA KOLOM] [SPASI] [TIPE DATA] [SPASI] [KETERANGAN] , [NAMA KOLOM] [SPASI] [TIPE DATA] [SPASI] [KETERANGAN]);
TUGAS 2
Tipe-tipe data pada database
1. Mysql

Tipe-tipe data yang didukung oleh mysql:
Ø TINYINT[(M)] [UNSIGNED] [ZEROFILL]
Integer yang sangat kecil jangkauan nilainya, yaitu -128 hingga 127. Jangkauan unsigned adalah 0 hingga 255.
Ø SMALLINT[(M)] [UNSIGNED] [ZEROFILL]
Integer yang kecil jangkauan nilainya, yaitu -32768 hingga 32767. Jangkauan unsigned adalah 0 hinga 65535.
Ø MEDIUMINT[(M)] [UNSIGNED] [ZEROFILL]
Integer tingkat menengah. Jangkauan nilainya adalah -8388608 hingga 8388607. Jangkauan unsigned adalah 0 hingga 16777215.
Ø INT[(M)] [UNSIGNED] [ZEROFILL]
Integer yang berukuran normal. Jangkauan nilainya adalah -2147483648 hingga 2147483647. Jangkauan unsigned adalah 0 hingga 4294967295.
Ø INTEGER[(M)] [UNSIGNED] [ZEROFILL]
Sama dengan INT.
Ø BIGINT[(M)] [UNSIGNED] [ZEROFILL]
Integer berukuran besar. Jangkauan nilainya adalah -9223372036854775808 hingga 9223372036854775807. Jangkauan unsigned adalah 0 hingga 18446744073709551615.
Ø FLOAT(precision) [ZEROFILL]
Bilangan floating-point. Tidak dapat bersifat unsigned. Nilai atribut precision adalah <=24 untuk bilangan floating-point presisi tunggal dan di antara 25 dan 53 untuk bilangan floating-point presisi ganda.
Ø FLOAT[(M,D)] [ZEROFILL]
Bilangan floating-point presisi tunggal. Tidak dapat bersifat unsigned. Nilai yang diijinkan adalah -3.402823466E+38 hingga -1.175494351E-38 untuk nilai negatif, 0, and 1.175494351E-38 hingga 3.402823466E+38 untuk nilai positif.
Ø DOUBLE[(M,D)] [ZEROFILL]
Bilangan floating-point presisi ganda. Tidak dapat bersifat unsigned. Nilai yang diijinkan adalah -1.7976931348623157E+308 hingga -2.2250738585072014E-308 untuk nilai negatif, 0, dan 2.2250738585072014E-308 hingga 1.7976931348623157E+308 untuk nilai positif.
Ø DOUBLE PRECISION[(M,D)] [ZEROFILL] dan REAL[(M,D)] [ZEROFILL]
Keduanya sama dengan DOUBLE.
Ø DECIMAL[(M[,D])] [ZEROFILL]
Bilangan floating-point yang “unpacked”. Tidak dapat bersifat unsigned. Memiliki sifat mirit dengan CHAR. Kata “unpacked'' berarti bilangan disimpan sebagai string, menggunakan satu karakter untuk setiap digitnya. Jangkauan nilai dari DECIMAL sama dengan DOUBLE, tetapi juga tergantung dai nilai atribut M dan D yang disertakan. Jika D tidak diisi akan dianggap 0. Jika M tidak diisi maka akan dianggap 10. Sejak MySQL 3.22 nilai M harus termasuk ruang yang ditempati oleh angka di belakang koma dan tanda + atau -.
Ø NUMERIC(M,D) [ZEROFILL]
Sama dengan DECIMAL.
Ø DATE
Sebuah tanggal. MySQL menampilkan tanggal dalam format 'YYYY-MM-DD'. Jangkauan nilainya adalah '1000-01-01' hingga '9999-12-31'.
Ø DATETIME
Sebuah kombinasi dari waktu (jam) dan tanggal. MySQL menampilkan waktu dan tanggal dalam format 'YYYY-MM-DD HH:MM:SS'. Jangkauan nilainya adalah '1000-01-01 00:00:00' hingga '9999-12-31 23:59:59'.
Ø TIMESTAMP[(M)]
Sebuah timestamp. Jangkauannya adalah dari '1970-01-01 00:00:00' hingga suatu waktu di tahun 2037. MySQL menampilkan tipe data TIMESTAMP dalam format YYYYMMDDHHMMSS, YYMMDDHHMMSS, YYYYMMDD, atau YYMMDD, tergantung dari nilai M, apakah 14 (atau tidak ditulis), 12, 8, atau 6.
Ø TIME
Tipe data waktu. Jangkauannya adalah '-838:59:59' hingga '838:59:59'. MySQL menampilkan TIME dalam format 'HH:MM:SS'.
Ø YEAR[(2|4)]
Angka tahun, dalam format 2- atau 4-digit (default adalah 4-digit). Nilai yang mungkin adalah 1901 hingga 2155, 0000 pada format 4-digit, dan 1970-2069 pada format 2-digit (70-69).
Ø CHAR(M) [BINARY]
String yang memiliki lebar tetap. Nilai M adalah dari 1 hingga 255 karakter. Jika ada sisa, maka sisa tersebut diisi dengan spasi (misalnya nilai M adalah 10, tapi data yang disimpan hanya memiliki 7 karakter, maka 3 karakter sisanya diisi dengan spasi). Spasi ini akan dihilangkan apabila data dipanggil. Nilai dari CHAR akan disortir dan diperbandingkan secara case-insensitive menurut default character set yang tersedia, kecuali bila atribut BINARY disertakan.
Ø VARCHAR(M) [BINARY]
String dengan lebar bervariasi. Nilai M adalah dari 1 hingga 255 karakter. Jika nilai M adalah 10 sedangkan data yang disimpan hanya terdiri dari 5 karakter, maka lebar data tersebut hanya 5 karakter saja, tidak ada tambahan spasi.
Ø TINYBLOB dan TINYTEXT
Sebuah BLOB (semacam catatan) atau TEXT dengan lebar maksimum 255 (2^8 - 1) karakter.
Ø BLOB dan TEXT
Sebuah BLOB atau TEXT dengan lebar maksimum 65535 (2^16 - 1) karakter.
Ø MEDIUMBLOB dan MEDIUMTEXT
Sebuah BLOB atau TEXT dengan lebar maksimum 16777215 (2^24 - 1) karakter.
Ø LONGBLOB dan LONGTEXT
Sebuah BLOB atau TEXT dengan lebar maksimum 4294967295 (2^32 - 1) karakter.
Ø ENUM('value1','value2',...)
Sebuah enumerasi, yaitu objek string yang hanya dapat memiliki sebuah nilai, dipilih dari daftar nilai 'value1', 'value2', ..., NULL atau nilai special "" error. Sebuah ENUM maksimum dapat memiliki 65535 jenis nilai.
Ø SET('value1','value2',...)
Sebuah set, yaitu objek string yang dapat memiliki 0 nilai atau lebih, yang harus dipilih dari daftar nilai 'value1', 'value2', .... Sebuah SET maksimum dapat memiliki 64 anggota.
2. Oracle
![]()
Datatype (tipe data) adalah klasifikasi atau jenis dari suatu informasi atau data tertentu. Setiap nilai yang dimanipulasi oleh Oracle memiliki sebuah tipe data masing-masing. Tipe data dari sebuah nilai tersebut diasosiasikan dengan nilai properti yang diset tetap. Properti ini menyebabkan nilai-nilai dari satu tipe data diperlakukan berbeda dengan nilai-nilai lain oleh Oracle.
Misalnya, Anda dapat menambahkan besaran nilai pada tipe data NUMBER, tetapi tidak dapat melakukan hal yang sama pada tipe data RAW. Bila Anda membuat sebuah tabel atau cluster, Anda harus menentukan tipe data untuk masing-masing kolom tersebut. Bila Anda membuat sebuah procedure atau function yang kemudian akan disimpan, Anda harus menentukan tipe data untuk setiap argumennya. Tipe data ini akan menentukan domain nilai disetiap kolom yang berisi argumen masing-masing yang dapat dimiliki procedure atau function tersebut. Sebagai contoh, kolom DATE tidak dapat menerima nilai 29 Feb (kecuali untuk tahun kabisat) atau nilai 2 atau ‘sepatu’. Setiap nilai akan ditempatkan dalam kolom dengan mengasumsikan tipe data dari kolom tersebut. Misalnya, jika
Anda memasukkan ’01-JAN-98 ‘ ke dalam kolom DATE, maka Oracle memperlakukan karakter string ’01-JAN-98′ sebagai nilai DATE setelah memverifikasi karakter string tersebut telah diterjemahkan dalam format tanggal yang valid.
Oracle Database menyediakan sejumlah built-in tipe data serta beberapa kategori untuk jenis yang ditentukan oleh pengguna, yang dapat digunakan sebagai tipe data. Penjelasan dari tipe data Oracle tiap-tiap tipe data akan dijelaskan pada bagian berikut:
v Tipe Data Karakter
Tipe data karakter terdiri atas tipe-tipe data CHAR, NCHAR, NVARCHAR2, VARCHAR2, VARCHAR, LONG, RAW dan LONG RAW. Penjelasan dari masing-masing tipe data dijelaskan sebagai berikut :
v CHAR
Tipe data CHAR dispesifikasikan dalam karakter string yang memiliki panjang tetap. Oracle memastikan bahwa semua nilai disimpan dalam sebuah kolom CHAR memiliki panjang yang ditentukan oleh ukuran (size). Jika Anda memasukkan nilai yang lebih pendek dari panjang kolom, Oracle akan mengisikan nilai kosong untuk panjang kolom yang tidak terisi nilai. Jika Anda mencoba untuk memasukkan nilai yang terlalu panjang untuk kolom, Oracle akan menampilkan pesan error.
v NCHAR
Tipe data NCHAR adalah tipe data Unicode-only. Bila Anda membuat sebuah tabel dengan kolom NCHAR, Anda akan diminta menentukan panjang kolom dalam karakter. Anda mendefinisikan karakter nasional saat Anda membuat (create) database Anda.
v NVARCHAR2
Tipe data NVARCHAR2 adalah tipe data Unicode-only. Bila Anda membuat sebuah tabel dengan kolom NVARCHAR2, anda akan diminta menyertakan jumlah maksimal karakter yang dapat diisikan kedalamnya. Oracle kemudian menyimpan setiap nilai dalam kolom persis seperti yang Anda tentukan itu, asalkan nilai tidak melebihi panjang maksimum kolom.
v VARCHAR2
Tipe data VARCHAR2 menetapkan string karakter variabel-panjang. Ketika Anda membuat kolom VARCHAR2, anda akan diminta menyertakan jumlah maksimal byte atau karakter data yang dapat diisikan kedalamnya. Oracle kemudian menyimpan setiap nilai dalam kolom persis seperti yang Anda tentukan itu, asalkan nilai tidak melebihi panjang maksimum kolom tentang kolom. Jika Anda mencoba untuk memasukkan nilai yang melebihi panjang yang ditentukan, maka Oracle akan menampilkan pesan error.
v VARCHAR
Jangan menggunakan tipe data VARCHAR. Gunakan VARCHAR2 sebagai gantinya. Meskipun tipe data VARCHAR saat ini identik dengan VARCHAR2, tipe data VARCHAR dijadwalkan akan didefinisikan ulang sebagai tipe data terpisah yang digunakan untuk string karakter variabel-panjang dibandingkan dengan perbandingan semantik yang berbeda.
v LONG
Jangan membuat tabel dengan menggunakan kolom LONG. Gunakan kolom LOB (CLOB, NCLOB, BLOB) sebagai gantinya. kolom LONG didukung hanya untuk kompatibilitas. kolom LONG menyimpan string karakter yang mengandung variabel-panjang sampai dengan 2 gigabyte -1 atau 231-1 byte. Kolom LONG memiliki banyak karakteristik kolom VARCHAR2. Anda dapat menggunakan kolom LONG untuk menyimpan string teks panjang. Panjang nilai LONG mungkin dibatasi oleh memori yang tersedia pada komputer Anda.
v RAW dan LONG RAW
Tipe data RAW dan LONG RAW menyimpan data yang tidak secara eksplisit dikonversi oleh Oracle Database ketika memindahkan data antara sistem yang berbeda. Tipe data ini dimaksudkan untuk data biner atau string byte. Sebagai contoh, Anda dapat menggunakan LONG RAW untuk menyimpan grafik, sound, dokumen, atau array data biner, yang penafsirannya tergantung pada penggunaan masing-masing.
3. Microsoft SQL server
![]()
· char(n) : Mendefinisikan string sepanjang n karakter. Bila n tidak didefinisikan maka panjang karakter adalah 1.
· varchar(n) : Mendefinisikan string sepanjang variabel n.
· binnary(n) : Untuk menyimpan bit pattern seperti heksadecimal. Contoh : 0x0fa9008e
· datetime : Mendefinisikan tanggal, menyimpan tahun, bulan, hari, jam, menit, detik dan seperseribu detik (milliseconds). Nilai tanggal sampai dengan 31 desember 9999.
· text : Menyimpan teks sampai dengan 2 GB. Text disebut juga dengan binary large objects (BLOBs)
· image : Mendefinisikan binary data untuk menyimpan image seperti GIF, JPG, TIFF, dll.
· money : Bilangan pecahan dengan 4 angka dibelakang koma. Digunakan untuk perhitungan moneter.
· smallint : Sama dengan int, membutuhkan 50% memory yang ditempati int.
· int : Mendefinisikan integer, bilangan bulat yang menampung angka sebanyak 4 byte.
· float(n) : Mendefinisikan angka pecahan (floating point). Nilai n adalah jumlah angka yang dapat ditampung . sysname
· real(n) : sama dengan float namun menempati memory 50% dari float.
· smalldatetime : sama dengan datetime hanya dengan presisi lebih kecil dimana satuan waktu terkecil adalah menit dan nilai tanggal sampai dengan 6 juni 2079.
· numeric(n,p) : Mendefinisikan angka pecahan baik fixed desimal ataupun floating point. Nilai n adalah jumlah bytes total dan p adalah presisi angka dibelakang koma. Numeric analog dengan DECIMAL(n,p).