
Studi kasus 4
Pada blog kali ini kita akan membuat algoritma membaca sumber data dari file dengan format csv, misalnya data yang berisi informasi pekerja.
1. Membuat File CSV
Baiklah pertama-tama kita buat terlebih dahulu file CSV menggunakan Microsoft Excel dengan contoh isian data seperti pada gambar di bawah ini:

Jika sudah dibuat, simpanlah dengan format CSV (Contoh "Studi Kasus 4 KDP.csv")
*Note: Pada kolom yang menggunakan angka harus dalam format general (jangan diberi format pemisah ribuan seperti titik dan koma)
2. Membuat Algoritma Pembaca CSV
Secara Sederhana Algoritma yang kita butuhkan akan tampak seperti ini
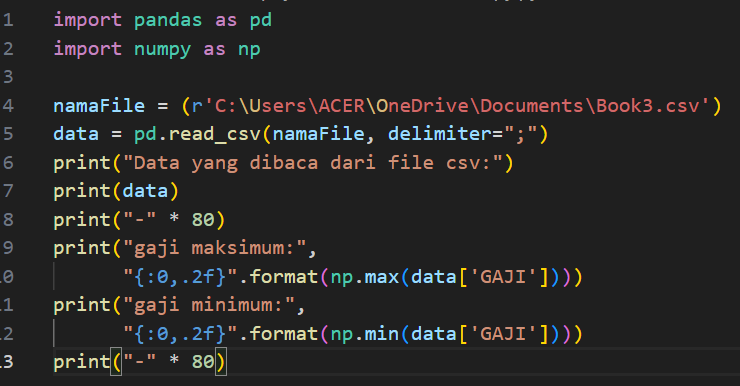
Algoritma ini bertujuan untuk membaca data pekerja dari file CSV dan menampilkan gaji maksimum dan minimum dalam format tertentu. Kita menggunakan dua library utama di Python, yaitu Pandas dan NumPy.
Berikut penjelasan setiap baris dan block yang kita gunakan
penjelasan pertama:
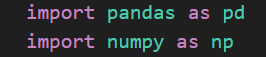
- import pandas as pd Pernyataan ini mengimpor library/modul "pandas" ke dalam kode, dan memberikan alias "pd" untuk memudahkan penggunaannya nanti. Library "pandas" adalah alat yang sangat berguna untuk melakukan pengolahan dan analisis data.
- import numpy as np Pernyataan ini mengimpor library/modul "numpy" ke dalam kode, dan memberikan alias "np" untuk memudahkan penggunaannya. Library "numpy" adalah alat yang kuat untuk melakukan komputasi numerik dan matematika yang kompleks.
penjelasan kedua:

- namaFile = (r'C:\Users\ACER\OneDrive\Documents\Book3.csv')
Baris ini mendefinisikan variabel "namaFile" dan memberikan nilai berupa path atau lokasi file CSV yang akan dibaca.Penggunaan tanda "r" di awal string menunjukkan bahwa ini adalah raw string, yang memungkinkan penggunaan karakter backslash tanpa harus menuliskannya sebagai double backslash.
- data = pd.read_csv(namaFile, delimiter=";")
Baris ini menggunakan fungsi "read_csv()" dari library "pandas" (alias "pd") untuk membaca file CSV yang ditentukan oleh variabel "namaFile".Parameter "delimiter" diberikan nilai ";" yang menunjukkan bahwa file CSV tersebut menggunakan tanda titik koma sebagai pemisah antar kolom.Hasil pembacaan file CSV tersebut disimpan dalam variabel "data".
penjelasan ketiga:

- print("Data yang dibaca dari file csv:")
Baris ini akan mencetak atau menampilkan teks "Data yang dibaca dari file csv:" ke output.Ini biasanya digunakan untuk memberikan konteks atau menjelaskan apa yang akan ditampilkan selanjutnya.
- print(data)
Baris ini akan mencetak atau menampilkan isi dari variabel "data" ke output.Sebelumnya, kode sebelumnya telah membaca data dari file CSV dan menyimpannya dalam variabel "data".Jadi, baris ini akan menampilkan keseluruhan data yang telah dibaca dari file CSV tersebut.
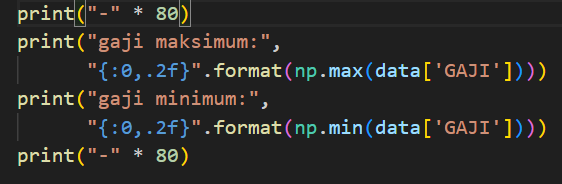
penjelasan keempat:
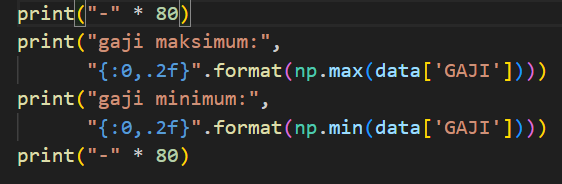
- print("- " * 80)
Baris ini akan mencetak tanda "-" sebanyak 80 kali.Ini biasanya digunakan untuk membuat garis pembatas atau separator visual di output.
- print("gaji maksimum:", "{:0.2f}".format(np.max(data['GAJI'])))
Baris ini akan mencetak teks "gaji maksimum:" diikuti dengan nilai gaji maksimum dari data yang tersimpan dalam kolom 'GAJI'.Fungsi np.max() digunakan untuk mencari nilai maksimum dari kolom 'GAJI'.Hasil dari np.max(data['GAJI']) akan diformat menjadi string dengan format "0.2f" (2 digit di belakang koma) menggunakan format().
- print("gaji minimum:", "{:0.2f}".format(np.min(data['GAJI'])))
Baris ini akan mencetak teks "gaji minimum:" diikuti dengan nilai gaji minimum dari data yang tersimpan dalam kolom 'GAJI'.Fungsi np.min() digunakan untuk mencari nilai minimum dari kolom 'GAJI'.Hasil dari np.min(data['GAJI']) akan diformat menjadi string dengan format "0.2f" (2 digit di belakang koma) menggunakan format().
- print("- " * 80)
Baris ini kembali mencetak tanda "-" sebanyak 80 kali untuk membuat garis pembatas.
3. Hasil Akhir:Program ini akan menampilkan tabel data pekerja, kemudian menampilkan gaji tertinggi dan terendah dalam data tersebut dengan format dua angka desimal.
kesimpulan:
Algoritma ini sangat berguna untuk analisis data dasar, khususnya dalam mencari nilai maksimum dan minimum dari sebuah dataset. Dengan memahami kode ini, Anda bisa menerapkan logika serupa untuk mengelola data lain yang serupa